
はじめに
こんにちは、Acsim 開発チームの池田です。
Acsim では Sentry を使ったエラー監視の運用を整備しています。アラートが来たら GitHub Issue に起票し、チームが優先度を判断して対応する、というフローです。
このフローを運用していくなかで、「起票されたIssueを誰かが開いてざっくり原因を把握する」というステップが積み重なっていることが課題になっていました。本記事では、その原因把握を起票と同時にDevinへ自動でやらせる仕組みを作った話を紹介します。
現在のSentry運用
Acsim のエラー対応フローはシンプルです。
- Sentry がエラーを検知
- エンジニアが緊急度を判断し、対応が必要なものは Sentry の UI から GitHub Issue を起票
- エンジニアが Issue を開いてざっくり原因を把握し、優先度を判断して対応
このフローは以前のSentry運用紹介記事で詳しく書いています。1
アラートの量は環境にもよりますが、プロダクションとステージングを合わせると一日に5件前後は来ることがあります。
課題
運用を続けている中で、エンジニアがClaude Codeなどに原因調査を依頼する手間が煩わしいという課題が出てきました。
具体的には、Issue を起票するたびに以下の手順が発生していました。
- ローカルで Claude Code を起動する
- Issue の内容をコピー&ペーストで渡す
- Sentry MCP を使った調査コマンドを実行する
- 調査結果を Issue にコメントしてもらう
調査自体はAIがやってくれるものの、そこに至るまでの単純作業が毎回積み重なっていました。
新しい運用フロー
仕組みとしてはシンプルです。
Before
Sentry エラー
↓
エンジニアが Sentry UI から GitHub Issue 起票
↓
エンジニアが Issue を開いてざっくり原因把握(手動 or 自分でエージェントに依頼)
↓
優先度判断・対応
After
Sentry エラー
↓
エンジニアが Sentry UI から GitHub Issue 起票(sentryラベル付与)
↓
GitHub CI がラベルを検知して Devin を起動
↓
Devin が Sentry MCP で原因把握
↓
調査結果を Issue にコメント
↓
エンジニアが判断・対応
エンジニアが Issue を開いたときには、すでに Devin の調査コメントがついている状態になります。
Devinがやること
Devin には以下のプロンプトを渡して動かしています。
- Issue の本文から Sentry の URL を抽出する
- Sentry MCP を使って調査を実施する
get_issue_detailsでエラーメッセージ・スタックトレース・影響ユーザー数などを取得analyze_issue_with_seerで AI による根本原因分析を実行- 必要に応じて
search_eventsで関連イベントを検索
- 調査結果を以下のフォーマットで GitHub Issue にコメントとして投稿する
## Sentry 1次調査結果
### エラー概要
- エラータイプ:
- エラーメッセージ:
- 発生頻度: (イベント数、影響ユーザー数)
- 初回発生:
- 最終発生:
### スタックトレース分析
### 根本原因の推定
(Seerの分析結果を含む)
### 影響範囲
### 推奨対応
(優先度と推奨される修正方針)
実際に Devin がコメントした例がこちらです。
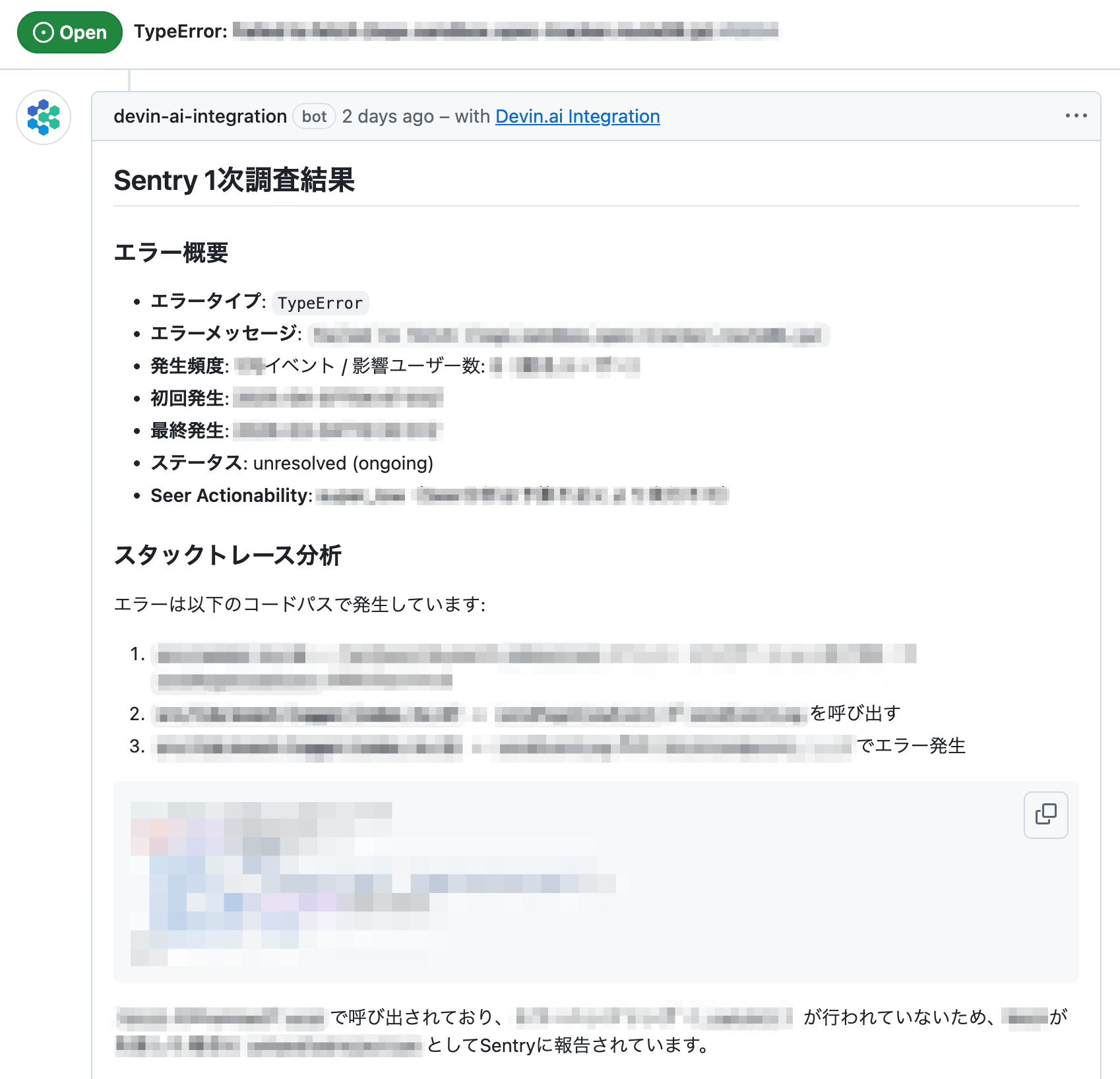
調査結果は Issue へのコメントとして投稿されるので、チームは Slack 通知を受けたときに既にサマリが読める状態です。
設計上の制約・トレードオフ
この仕組みを作るにあたって、実装手段をいくつか検討しました。「どれで実現するか」の判断に至った経緯を書きます。
検討した選択肢
| 案 | 概要 |
|---|---|
| A | Claude Code Actions + Sentry REST API 直叩き |
| B | Claude Code Actions + Sentry MCP |
| C | Devin + Sentry MCP(組織共有) |
案A:Sentry REST API 直叩きを選ばなかった理由
Sentry は REST API を公開しており、技術的には Claude Code Actions から直接叩くことは可能です。
ただ、これを採用すると以下のコストが乗ってきます。
- Secrets 管理: Sentry の認証トークンを CI に安全に渡す設計が必要。組織用 Integration Token の発行・スコープ設計・ローテーション運用まで含めると設計責任が重い
- 実装コスト: 必要な情報(スタックトレース、関連イベント、release/environment など)は複数エンドポイントを組み合わせる必要があり、取得データを読みやすい形に整形するロジックも自前になる
- 保守コスト: Sentry の仕様変更への追従、rate limit 対応なども自前
原因把握の省力化が目的なのに、実装側のコストが膨らむ構成になってしまうため、採用しませんでした。
案B:Claude Code Actions + Sentry MCP を選ばなかった理由
MCP を使えば整形ロジックや複数エンドポイントの問題は解決します。しかし Claude Code Actions(GitHub Actions 上での実行)で MCP を使う場合、以下が残ります。
- MCP の認証情報を Actions の環境変数・Secrets として注入する設計が必要
.mcp.jsonの管理、--mcp-config経由での受け渡しなど、CI 側の設定が増える
そもそも今回の文脈では、Sentry の認証がもともと各自の Google アカウントに紐づいていたため、「認証情報をどう渡すか」が当初の懸念でした。Claude Code Actions ではこの問題を自前で解決する必要があります。
案C:Devin + Sentry MCP(組織共有)を選んだ理由
今回採用した構成です。
Devin は MCP の接続を組織単位で共有できます。一人のメンバーが Sentry MCP を OAuth 認証して登録すれば、Devin API 経由でも同じ MCP が使えます。2 つまり、各エンジニアが個別にトークン設定をする必要がない。認証情報をどう渡すかという課題を、この仕組みでそのまま回避できました。3
CI 側でやっていることは、sentry ラベルが付いたら Devin を起動するワークフローを追加しただけです。Devin 側のセットアップも、既存の MCP 共有の仕組みに乗るだけで完結しました。
name: "[Issue] Devin Sentry Investigation"
on:
issues:
types: [labeled]
jobs:
request_devin_implementation:
runs-on: ubuntu-latest
steps:
# 1. ラベル名に応じてDevinへ渡すプロンプトを組み立てる
- name: Build prompt based on label
id: build_prompt
run: |
case "$LABEL_NAME" in
"sentry")
PROMPT="..." # Sentryの一次調査プロンプト
;;
*)
echo "skip=true" # 対象外ラベルはスキップ
exit 0
;;
esac
# 2. Devin API にセッション作成リクエストを投げる
- name: Request Devin session
run: |
curl -X POST "https://api.devin.ai/v1/sessions" \
-H "Authorization: Bearer $DEVIN_API_KEY" \
-d @/tmp/devin_payload.json
# 3. IssueにDevinセッションのURLをコメントする
- name: Add comment to issue
run: |
gh api ... -f body="Devinに調査依頼を送信しました。進行状況は $SESSION_URL で確認できます。"
ラベルで分岐することで将来的な拡張もしやすく、Devin API の呼び出し自体は POST 1回で完結します。
運用結果
定性的な話になりますが、主に以下の効果がありました。
原因把握の初動の手作業が減った Issue を開いたときに既にサマリがある状態なので、Sentry へ移動してざっくり何が起きているか把握するフェーズがほぼなくなりました。
エンジニアが判断に集中できる 調査結果を読んで「対応するか・しないか・いつやるか」を判断するだけになりました。週に何件もある定型調査が積み重なっていたコストが、体感として下がっています。
まとめ
Sentry の原因把握を Devin に自動化した話を紹介しました。
技術的なポイントを整理するとこうなります。
- ラベルトリガーで起動 — GitHub Issue に
sentryラベルが付くと CI が発火し、Devin が起動する - Sentry MCP を組織共有 — 個人の認証情報を CI に配布せず、Devin の組織共有 MCP に認証を集約した
- Claude Code Actions ではなく Devin を選んだ理由 — 認証管理・継続実行・実装コストの観点で、今回の目的(原因把握の省力化)には Devin の構成が適していた
今後は過去の対応結果から、優先度とチームアサインの判断、優先度の高いエラーは自動でチームにメンションするなどの拡張も行えたらと思っています。
同じような課題を感じている方の参考になれば幸いです。
参考
Footnotes
-
Sentryを使ったエラー監視の運用 — Acsim での Sentry 運用フローの詳細はこちらで紹介しています。 ↩
-
Devin MCP ドキュメント — OAuth 認証した MCP は組織内で共有されると明記されています。 ↩
-
Sentry MCP 公式ドキュメント — Sentry が提供するリモートホスト型 MCP サーバーの概要と OAuth 認証フローについて記載されています。Sentry MCP の背景についてはこちらのブログも参考になります。 ↩