
はじめに
こんにちは、Acsim 開発チームの笹沢です。
いきなりですが、皆さんの組織では Sentry の運用ルールをしっかり決めていますか?
「アラートは設定しているけど見過ごされがち」「特定の人だけがチェックしていて属人化している」「ルールはあるけど形骸化している」など、いろいろ課題を抱えているのではないでしょうか。
私たちのチームでも Sentry を導入してエラー監視の仕組みはできたものの、運用ルールを決めておらずいくつかの課題を抱えていました。
本記事では、アラートの目的を再考することを出発点とし、アラートの見過ごしが起きにくい運用ルールの考え方と設計をご紹介します。
状況
まず、私たちのチームとプロダクトの状況を説明します。
チーム構成
- 開発者は10人
- 専任の SRE はおらず、インフラからアプリケーションまで全員が担当
プロダクト
- 運用開始から約1年
- Full-Stack TypeScript
Sentry の導入状況
- プロダクト立ち上げ時から導入済み
- フロントエンド・バックエンド両方を監視対象としている
抱えていた課題
Sentry を導入したものの、運用面ではいくつかの課題を抱えていました。
- 特定の人しかアラートを見ないため、見過ごしリスクがある
- Sentry のステータス(Ongoing/Resolved/Archivedなど)の使い分けが曖昧
- 優先度基準がなく、どのエラーから対応すべきか判断できない
- ワークフローが標準化されておらず対応方法が人によって違う
これらの課題は運用ルールをしっかりと決めて、チームで共有することによって解決できます。
アラートの運用で最も避けたいこと
運用ルールを決めるにあたって、まずはアラートの運用において最も避けるべき事態は何か、そしてそれを回避するために満たすべき事柄は何かを考えました。
そもそもになりますがアラートは何のためにあるのでしょうか。ChatGPT に聞いてみました。
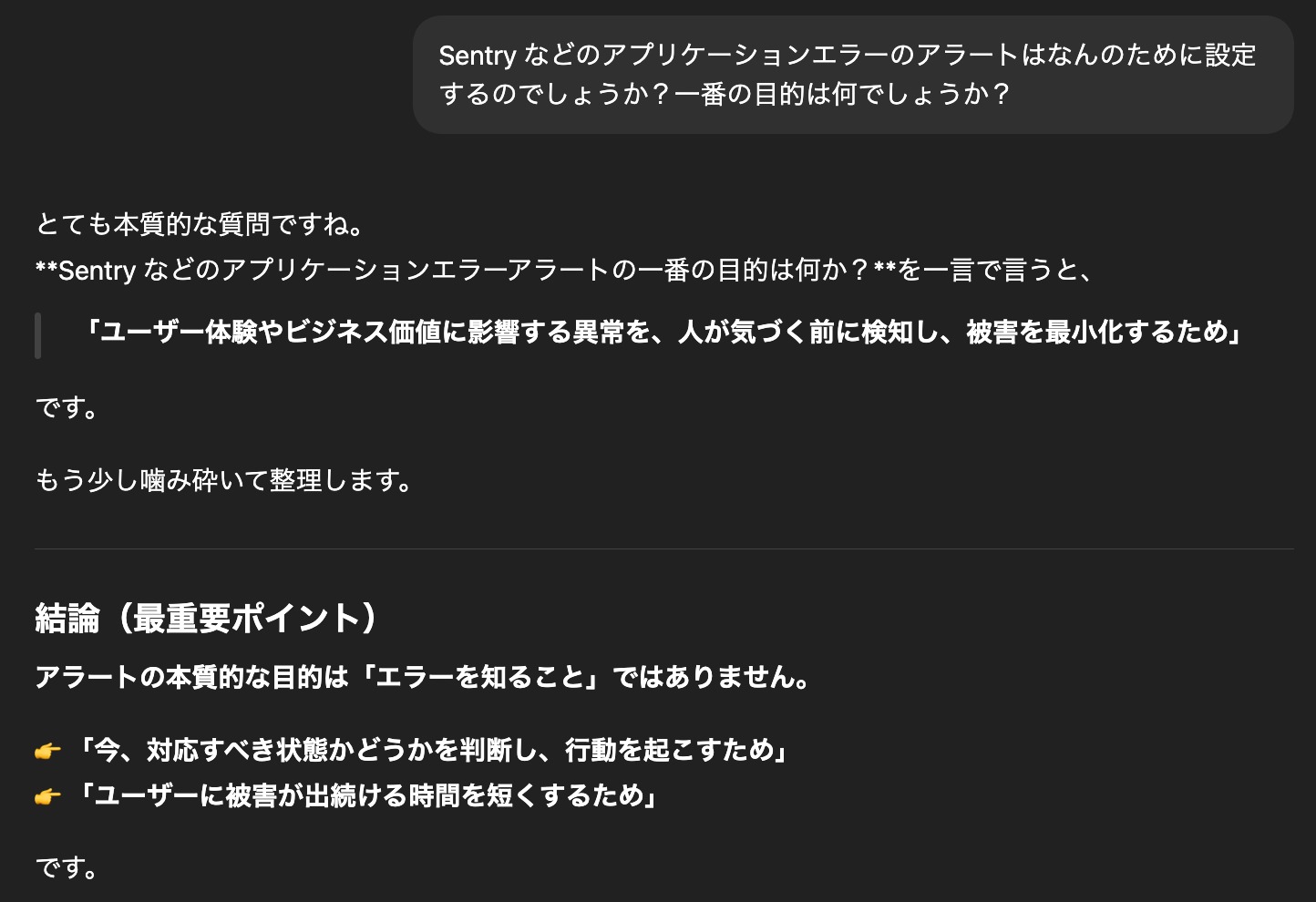
アラートの本質的な目的は「エラーを知ること」ではありません。
👉 「今、対応すべき状態かどうかを判断し、行動を起こすため」
👉 「ユーザーに被害が出続ける時間を短くするため」
これは核心を突いた回答だと思います。アラートの本質はエラーの詳細を把握することではなく、直ちにアクションが必要かどうか判断するフックとして機能することです。
アラートが誰にも確認されず重大インシデントに発展することは最も回避しなければいけない事態だと言えます。
アラートの見過ごしを防ぐために
ではなぜアラートの確認が漏れるのでしょうか。これにはいくつかの要因があると思います。
あくまで私の経験ですが、「アラートを確認するハードルが高い」というのが1つの要因だと感じています。責任感の強い人ほど、アラートを最初に拾った人がそのまま原因調査や根本解決まで行わなければならないと考えてしまいがちです。そうすると、手元のタスクで手一杯だったりして、ついアラートのチェックをおろそかにしてしまいます。
こうした認識から、アラートを確認するハードルを可能な限り下げることを優先して運用ルールを設計するようにしました。
何はともあれ公式ドキュメント
私自身、Sentry はそこそこ触ってきたものの、Issue のステータスやプライオリティ、アラートの種類について詳しくありませんでした。運用ルールを設計するにあたり、まずは公式ドキュメントをしっかり読み込むことにしました。
参考になったドキュメントは以下のとおりです。運用を設計する際にはぜひ一読することをおすすめします。特に Issue のステータスの種類と遷移先、そのトリガーは把握しておくとよいでしょう。
運用ルールの設計
これらを踏まえて、運用ルールを設計しました。最初にアラートに気付いた人が行う「1次対応」と週次でチームで確認する「2次対応」という大きく2ステップで運用しています。
1次対応を極限までシンプルに
アラートが届いたら何よりも優先してチェックしてほしいです。そのため1次対応ではアラート確認のハードルを下げるため、やることを最小限に絞りました。
- Slack に通知が来たら 👀 リアクションをつける
- Sentry を開いて内容をざっくり確認する
- Severity Level を判定する
- GitHub Issue を作成する
- Sentry で「Mark reviewed」にする
- Slack に ☑️ リアクションをつけて完了
ポイントは原因調査を1次対応に含めないことです。アラートの多くは緊急対応が不要なものです。1次対応で「誰かが確認した」という事実を残すことが目的であり、原因の深掘りや修正は後回しにします。これにより、誰でもアラート対応に参加できるようになります。
Severity Level で緊急度を判断可能に
1次対応で原因調査は行わないと説明しましたが、そのアラートが重大なインシデントの兆候であった場合は、即座に原因調査を行わなければなりません。そこで、「Severity Level」を導入しそのアラートの緊急度を判断可能にしました。1次対応ではアラートがどの Level に属するかチェックし、後日対応でよいか即時にチームで協力を要請するか判断します。
| レベル | 概要 | 具体例 |
|---|---|---|
| SEV-1 | 非常に大きな影響がある重大なインシデント |
|
| SEV-2 | サービス利用に重大な影響を与えるインシデント |
|
| SEV-3 | 安定性の問題またはユーザに影響を及ぼす軽微な問題 |
|
| SEV-4 | 対処が必要な問題だが、ユーザのサービス利用には影響しない |
|
| SEV-5 | ユーザがサービスを利用する能力に影響を与えない、外観上の問題またはバグ |
|
Severity Level の定義には以下のドキュメントを参考にしました。
アサインと優先度の決定は週次で
1次対応によりアラートはチェックされますが、アサインや優先度判定、原因調査は行われません。そこで週次ミーティングで以下を行うようにしました。
- Sentry で
is:for_reviewフィルターを使い、未確認 Issue を確認 - 対応が必要なものは GitHub Issue を作成・更新
- アサインと優先度を決定
このミーティングでも原因の深堀りは行いません。軽くあたりをつけるまでにして、アサインと優先度の決定に集中します。ミーティングは多くのメンバーを拘束するため、なるべく短時間で終わらせるに限ります。原因調査に深入りしすぎるとミーティングが長引いてしまうため、こうした認識はチーム全員で共有しておく必要があります。
Issue 管理は GitHub で
Sentry には GitHub Issue へのインテグレーション機能があり、Sentry の Issue 画面からシームレスに GitHub Issue を作成できます。私たちのチームではタスク管理に GitHub を利用しているため、基本的に Sentry の Issue 管理機能は使わずに GitHub 上でアサインを割り当てたり、優先度を入力したり、対応ログを残したりしています。
Sentry から作成した GitHub Issue には Sentry というラベルを付与しているため、GitHub Project で Sentry ボードを作成して管理しています。
ワークフロー全体像
最後に、ワークフローの全体像を掲載しておきます。
まとめ
このワークフローを導入してから2ヶ月経ちました。チームも慣れて、しっかりとアラートの運用が回るようになりました。
アラートが放置されることはなくなりましたし、特定の人しかアラートを見ない状況から、先に気づいた人が対応できる風土ができました。アラート対応は開発者にとってストレスになりがちですが、このストレスをチーム全体でコントロールすることはチームの健全性にも繋がります。
まだまだ改善の余地はあるのでチームで議論しながら継続的に改善していきたいと思います。
本記事が同じような課題を抱えているチームの参考になれば幸いです。