
私たちが開発しているAcsimは、要件定義を支援するプラットフォームです。
その中核機能のひとつにナレッジベースがあります。ユーザーがアップロードしたドキュメントをAIが読み込み、要件定義の対話の中で参照できるようにする仕組みです。
これまでナレッジベースはPDF、Word、Excel、テキストファイル、Markdown等に対応していました。 しかし、ある課題が見えてきました。
顧客の重要な知識が、PowerPointに詰まっている。
SaaS製品の仕様書、業務フローの説明資料、システム構成の概要図。
こうしたドキュメントの多くはPPTX形式で作られています。
そしてPPTXの特徴は、テキストだけでなく図表やフローチャートが情報の核であることです。
本記事では、PPTXファイルをナレッジベースに取り込むために、どのような技術的課題があり、どう設計・実装したかを共有します。
なぜPPTXの取り込みは難しいのか
最初にぶつかった壁は、Amazon Bedrock Knowledge BaseがPPTXを直接サポートしていないということでした。
Bedrock Knowledge Baseが対応しているファイル形式はPDF、TXT、MD、HTML、DOC/DOCX、XLS/XLSXなどです。PPTXはこのリストに含まれていません1。
仮にテキストだけを抽出してナレッジベースに登録する方法を考えた場合、別の問題があります。
AcsimのナレッジベースはBedrock Knowledge BaseとTitan Text Embeddings V2を使っていますが、これはテキストモデルです。図表を「見る」ことはできません。
たとえば、Microsoft製のOSSツール「markitdown」を使えばPPTXから直接Markdownを生成できます。しかし試してみると、フローチャートの各図形が個別のテキストとして抽出され、図としての関係性が完全に失われてしまいました。
「承認」「差し戻し」「完了」といった個々のテキストは取れても、それらが矢印でどうつながっているのかが分からない。これではナレッジベースに入れても意味のある検索結果は返せません。
つまり、PPTXの取り込みにおける本質的な課題は 「視覚的な情報をどう保持するか」 でした。
Foundation models as a parserという選択肢
この課題に対する答えは、Bedrock Knowledge BaseのAdvanced Parsing機能の中にありました。
Bedrock Knowledge Baseには3つのパーシングオプションがあります。
- Default Parser: テキストファイルからテキストのみを抽出する。図表や画像は無視される
- Amazon Bedrock Data Automation: AWSのデータ自動化サービスを使う(ただしPPTX未対応)
- Foundation models as a parser: LLMを使ってPDFの図表・画像を解析し、構造化テキストに変換する
3番目の「Foundation models as a parser」が、私たちが求めていたものでした。
この機能は、Knowledge Baseに登録されたPDFファイルを、指定したFoundation model(今回はClaude Sonnet 4.5)で解析します。テキストだけでなく、図表、チャート、画像の中の情報もLLMが読み取り、テキストとして抽出してくれます。
つまり、PPTXをPDFに変換してからKnowledge Baseに登録すれば、Foundation models as a parserが図表の内容まで解析してくれるのです。
実際に、業務フロー図を含むPPTXファイルを解析した結果の一部を紹介します。
以下がPPTXに含まれていた元のフロー図です。
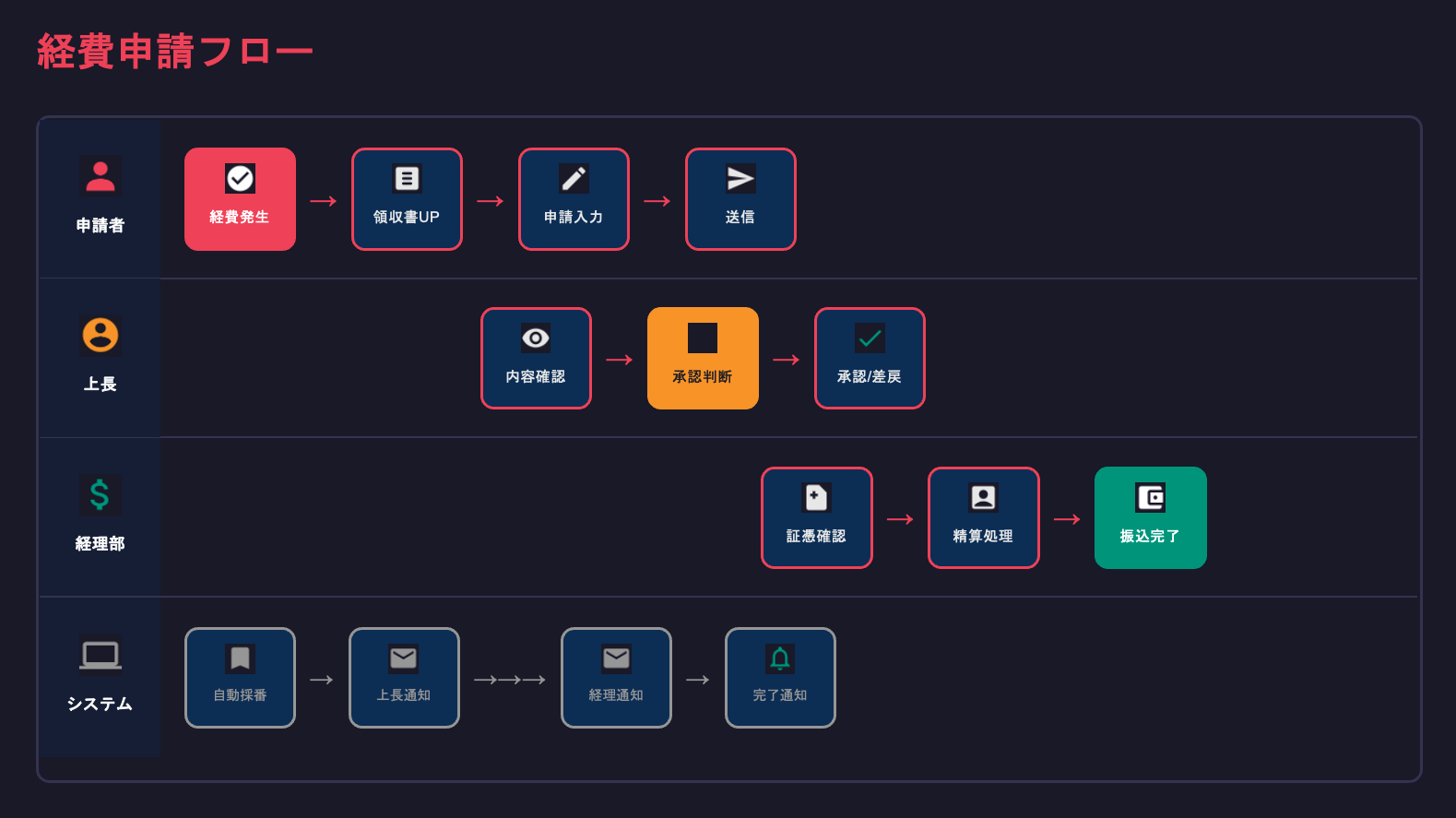
これをFoundation models as a parserが解析すると、次のようなテキストが得られます。
## 経費申請フロー
### 申請者
経費発生 → 領収書UP → 申請入力 → 送信
### 上長
内容確認 → 承認判断 → 承認/差戻
### 経理部
証憑確認 → 精算処理 → 振込完了
### システム
自動採番 → 上長通知 → 経理通知 → 完了通知
---
**フローの流れ:**
1. 申請者が経費発生後、領収書をアップロードし、申請入力して送信
2. システムが自動採番し、上長へ通知
3. 上長が内容確認し、承認判断を行い、承認または差戻
4. 承認後、システムが経理部へ通知
5. 経理部が証憑確認、精算処理を行い、振込完了
6. システムから完了通知
単なるテキスト抽出では「経費発生」「領収書UP」「承認」といった断片しか得られなかったものが、Foundation models as a parserではフローの流れ、担当者の役割、ステップ間の関係性まで構造化されたテキストとして抽出されています。これがナレッジベースの検索精度に直結します。
なぜこのアプローチを選んだか
Foundation models as a parserを採用した主な理由は3つです。
- ファイルサイズ上限が大きい: 50MB/fileまで対応。Amazon BedrockのConverse APIは検証当時(2025年12月)4.5MBに制限されていた2。AnthropicのMessages APIは32MB(総リクエストサイズ)3で、高画質PDFを扱う余裕が最も大きい
- AWS統合: IAMやCloudWatchとの統合が自然で、API Key管理が不要。既存のBedrock契約をそのまま活用できる
- Worker実装がシンプル: PDFへの変換とS3へのアップロードだけで済み、解析処理はKnowledge Base側で自動実行される
他にもいくつかのアプローチを検討しました。
- Amazon BedrockのConverse API: 検証当時(2025年12月)ドキュメントサイズが4.5MBに制限されていた2。現在はClaude 4以降のモデルでPDFに対してこの制限が撤廃されている(ただし100ページ/リクエストの制約あり)4
- AnthropicのMessages API: 32MB(総リクエストサイズ)まで対応するが、Anthropicとの直接契約やAPI Key管理が必要になる
- markitdown(Microsoft製OSS): 前述の通り、フロー図の関係性が失われる
- Azure Content Understanding: フローチャート解析にも対応するが、マルチクラウド運用の複雑性が増す
結果として、ファイルサイズの余裕、AWS統合のシンプルさ、実装コストの低さを総合的に判断し、Foundation models as a parserを採用しました。
PPTX → PDF → Knowledge Baseのアーキテクチャ
最終的に設計したアーキテクチャの全体像です。
処理の流れはこうなります。
- ユーザーがPPTXファイルをアップロードすると、S3に保存され、Background Jobが作成される
- WorkerがS3からPPTXをダウンロードし、LibreOfficeでPDFに変換する
- 変換後のPDFをKnowledge Base専用のS3バケットにアップロードする
- Bedrock Knowledge Baseが自動的にFoundation models as a parserでPDFを解析し、インデックスを構築する
Worker自体はPDFの変換とアップロードだけを担当し、図表の解析はKnowledge Base側に任せるシンプルな設計です。
ファイルサイズの工夫
PPTX→PDF変換には、LibreOfficeをDockerコンテナ内で動かす方式を採用しました。
Foundation models as a parserには50MB/fileの制限があります。
PPTXをPDFに変換するとファイルサイズが増加する傾向があるため(検証したサンプルでは約2.3倍。画像の多さやスライド構成により変動します)、以下のフローで対応しています。
- 変換後のPDFが50MB以内 → そのままアップロード(画質を維持)
- 50MBを超過 → LibreOfficeのPDF Export Filterで圧縮を実施
- 圧縮後も50MBを超過 → エラーとして処理
高画質を維持しつつ、制限に収まらない場合だけ圧縮するという方針です。
コストと制約のリアル
Foundation models as a parserは強力ですが、トレードオフもあります。
コスト
Foundation models as a parserは、指定したLLMでPDFを解析するため、Default Parserと比べて大幅にコストが増加します。AWSの公開料金として、たとえばClaude Sonnet 4.5を使用する場合は入力 $0.003 / 1,000トークン、出力 $0.015 / 1,000トークンが発生します(2026-02-24時点・リージョンにより変動)5。ページ数や図表の量に応じてトークン消費が増えるため、ファイルあたりのコストはDefault Parserの数百倍になることもあります。
そして重要なのは、Foundation models as a parserはKnowledge Base全体に適用されるという点です。PPTXだけでなく、既存のPDFファイルもすべてこのパーサーで処理されるようになります。
裏を返せば、既存のPDFファイルも図表解析の恩恵を受けられるようになったとも言えます。導入前にファイル数・ページ数から概算コストを試算しておくことをお勧めします。
モデル固定の制約
Foundation models as a parserで使用するモデルは、Knowledge Base作成時に固定され、後から変更できません。Chunking strategyも同様です。
たとえば将来、より高性能なモデルがリリースされた場合でも、既存のKnowledge Baseではそのモデルは使えません。新しいKnowledge Baseを作り直す必要があります。
トレードオフの判断
- コスト増 vs 図表解析の付加価値: Default Parserと比べて大幅なコスト増にはなりますが、スライドの図表情報が検索可能になる付加価値と比較して許容範囲と判断しました
- AWS依存の深化 vs 実装のシンプルさ: PDF解析をKnowledge Base側に任せることでWorkerの実装はシンプルになりますが、他のLLMプロバイダ(OpenAI、Google等)への切り替えには設計の大幅な見直しが必要になります
これらは「今の要件」に対する判断であり、状況が変われば見直す可能性もあります。
まとめと今後
PPTXサポートの本質は、単にファイル形式を追加することではなく、スライドの視覚情報を検索可能にすることでした。
Foundation models as a parserは、LLMの「画像を読む力」をドキュメント解析に活用するアプローチです。PPTXに限らず、図表を多用するPDFドキュメント全般に対して有効です。
Foundation models as a parserの導入を検討している方は、以下のポイントを事前に確認することをお勧めします。
- コスト: Default Parserと比較して大幅にコストが増加する。既存ファイルにも適用される点に注意
- モデルの固定: Knowledge Base作成時の選択が永続的な決定になる。変更するにはKnowledge Baseの再作成が必要
- 対応形式: Foundation models as a parserが解析するのはPDFのみ。他の形式は事前にPDFへの変換が必要
Footnotes
-
Send a message with the Converse API operations - Amazon Bedrock(「メッセージ」セクション内に記載) ↩ ↩2
-
API restrictions - Amazon Bedrock(Claude 4以降のモデルではPDFに対して4.5MBの制限が適用されない旨が記載) ↩